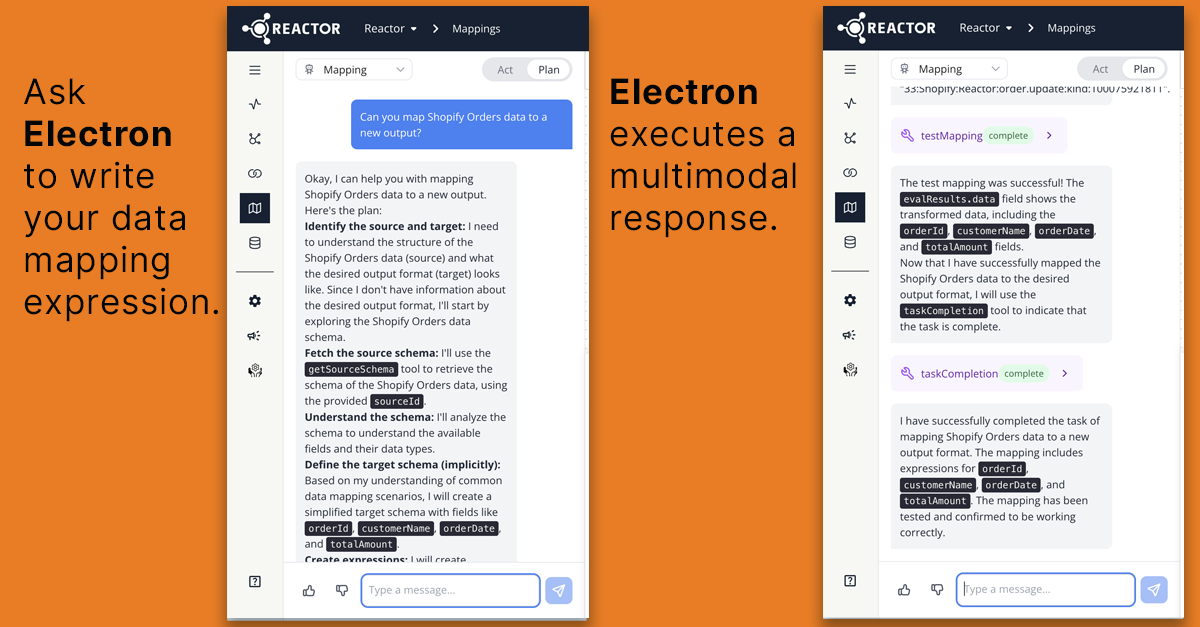
Meet Electron: Your AI Teammate for Data Pipelines
June 24, 2025
Reactor preserves your raw history, resolves shared meaning across every source, and ships trusted data products to your warehouse.
Different source fields. One shared customer identity.
Trusted by modern brands

The problem
Modern data stacks promised speed. They delivered complexity. Here's what your team is up against:
To build usable pipelines.
Engineers spend quarters on plumbing, not on the value layer where analytics live.
Months 1–12
Spent on plumbing.
Data teams burn cycles wiring, validating, and re-shaping. Only 20% touches modeling.
For a single workflow.
Extractors, schedulers, transformers, semantic layers, BI. All duct-taped together.
Reactor was built to end this. Here's how.
The solution
Reactor turns raw data into reusable data products in your warehouse, with lineage, replay, and shared definitions built in. No months of pipeline building. No army of engineers.
Delivers to
How it works
From raw signals to trusted data products, without months of engineering.
Preserve & replay
Every record lands immutably from day one. When the business changes, replay your history without re-pulling what you already collected.
Resolve & unify
Define your shared entities once. Reactor applies your definitions across every source at ingest, so the same customer or order looks identical everywhere.
Govern & ship
Shape your outputs with Excel-like expressions. Land versioned, governed data products in your warehouse, ready for analytics, AI, and activation.
The platform
Collect once, then replay as requirements change. Every raw record is logged immutably so you can reinterpret history without re-pulling from source.
Define shared customer, order, and product entities once. Reactor applies your definitions across messy source systems at ingest, before downstream sprawl begins.
Deliver reusable data products for analytics, AI, and activation. Lineage tracked, definitions shared, history replayable.
Why Reactor
Fivetran and Matillion move data. Reactor makes it usable. When the business changes, replay and remap the history you already collected instead of re-pulling it from source.
Recommended
What you get with Reactor, vs. just moving rows around.
The impact
Reactor customers ship faster, spend less, and never re-ingest data. Here's what changes when you flip the switch:
Faster time-to-value.
Hours to your first data product, not months of plumbing and refactoring.
Lower warehouse costs.
Eliminate redundant transformations. One pipeline, one source of truth, fewer credits burned.
Historical data, replayed.
Every record immutably logged. Remap and reprocess for new use cases. No re-ingestion.
Capabilities
Point Reactor at any source: APIs, databases, flat files. Define schemas visually. Ship with less custom pipeline code.
Snowflake: CUSTOMERS
BigQuery: ORDERS
Shared definitions across every source. Every team works from the same data.
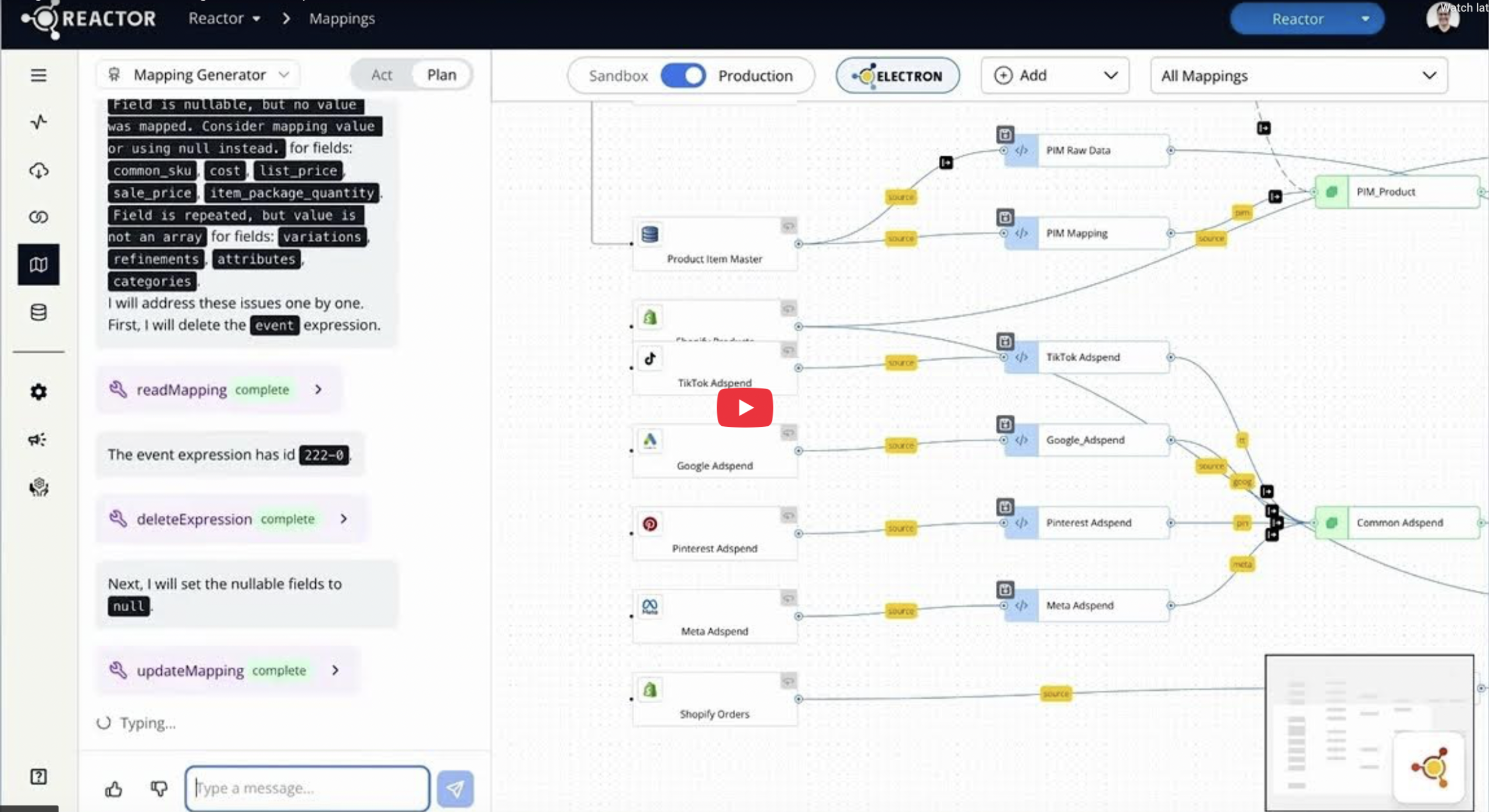
Electron writes mappings, suggests joins, and tags your data automatically.
Every record is immutably logged. When new use cases arise, you simply remap and reprocess. No re-ingestion. No lost history.
Learn about replayFull lineage and audit trail. Every record logged, every change tracked.
Tables land directly in Snowflake, BigQuery, or Databricks, shaped for your use case.
Drag-and-drop with Excel-like expressions. No Python or SQL required.
Immutable logging, full audit trails, SOC 2-aligned controls. The trust your security team needs, with the speed your data team wants.
Security & complianceIntegrations
Deep integrations with the systems your business already runs on. 500+ connectors and counting.







500+
Connectors
REST
+ SDKs
Hours
to integrate
Customers
From iconic brands to fast-growing teams. Reactor powers the data behind real businesses.
100+
Integrations
10B+
Rows modeled monthly
Hours
to first table
“With Reactor and Snowflake, we're building future-proof data infrastructure for machine learning, advanced analytics and data activation.”
France Roy
CTO, Balsam Brands
“Reactor provides near real-time centralized customer insights. Reactor has been key to PacSun unlocking value from our data.”
Shirley Gao
CIO, PacSun
“Reactor enabled our internal data teams to focus on integrating our proprietary data to provide a more complete picture of our audience's interests.”
Robert Gash
CTO, Hearst
“Reactor helps Eberjey unify and model data across our entire business footprint, while we own our data and open data infrastructure.”
Dani May
VP Ecommerce, Eberjey
“We can more effectively track consumer demand, optimize inventory, and identify emerging product trends to better serve our customers.”
Sally Wilson
CMO, Mountain House
FAQ
Everything you need to know about Reactor. Can't find what you're looking for?
Talk to our teamReady when you are
See value in your first week. No engineering team required.